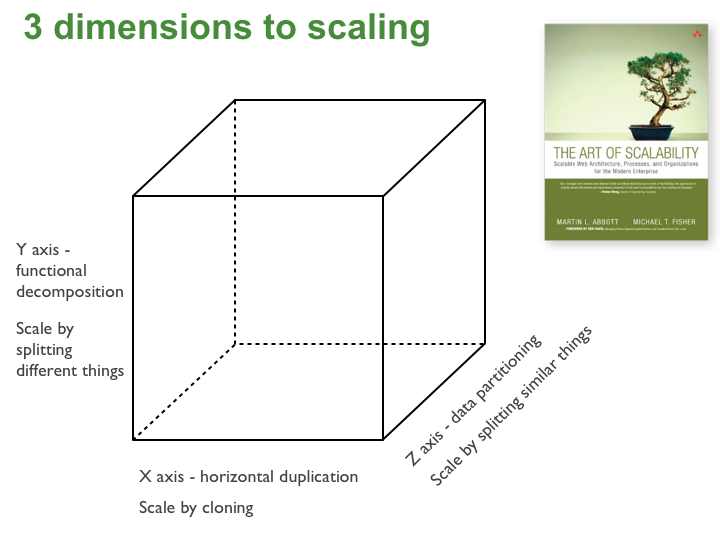
 x-axis: horizontal duplication
x-axis: horizontal duplication
scale by cloning
eg. load-balander + auto-scaling
y-axis: functional decomposition
scale by splitting different things
eg. monolith -> microservices (compare with Model: 5 service disintegrators #3 scalability and throughput)
z-axis: data partitioning
scale by splitting similar things
“sharding” eg. split data per product-id (shard 1 = product-id 0 - 99, shard 2 = product-id 100 - 199, …) eg. split data per time (aka “archiving older data”)
(src: Article: The Scale Cube)